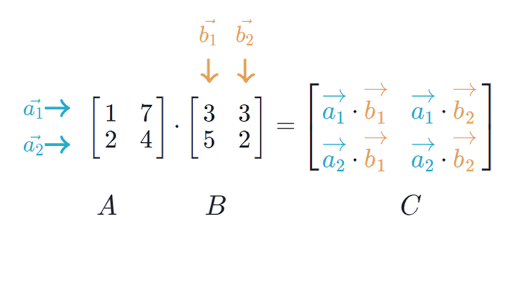Определение. Функция \(f: \mathbb{R}^n \to \mathbb{R}^m\) называется линейной, если для неё выполнено:
Например, линейными являются:
Линейная алгебра занимается изучением линейных функций.
Из одних лишь двух пунктов в определении можно вывести много полезных свойств:
Можно показать, что любую линейную функцию \(f: \mathbb{R}^n \to \mathbb{R}^m\) можно представить в следующем виде:
\[ f(x) = \begin{pmatrix} a_{11} x_1 + a_{12} x_2 + \ldots + a_{1n} x_n \\ a_{21} x_1 + a_{22} x_2 + \ldots + a_{2n} x_n \\ \ldots \\ a_{m1} x_1 + a_{m2} x_2 + \ldots + a_{mn} x_n \\ \end{pmatrix} \]
Матрицы ввели просто как очень компактную запись этих коэффициентов \(a_{ij}\).
\[ A = \begin{pmatrix} a_{11} & a_{12} & \ldots & a_{1n} \\ a_{21} & a_{22} & \ldots & a_{2n} \\ \vdots & \vdots & \ddots & \vdots \\ a_{m1} & a_{m2} & \ldots & a_{mn} \\ \end{pmatrix} \]
Каждой линейной функции \(f\) из \(\mathbb{R}^n\) в \(\mathbb{R}^m\) соответствует какая-то матрица \(A\) размера \(n \times m\) (первое число это количество строк, второе — столбцов) и наоборот. Элемент на пересечении \(i\)-ой строки и \(j\)-го столбца будем обозначать \(A_{ij}\). Не перепутайте.
Если вектор — это упорядоченный набор скаляров, то матрицу можно рассматривать как вектор векторов. Вектор, в частности, можно представить как матрицу, у которой одна из размерностей равна единице — тогда его называют вектор-столбец либо вектор-строка.
typedef vector<vector<int>> matrix;Ещё есть тензоры — ими называют все объекты ещё более высокого порядка: векторы матриц (трёхмерный тензор), матрицы матриц (четырёхмерный тензор) и векторы матриц матриц и так далее.
У тензоров есть своя интересная алгебра, но в контекстах, в которых с ними сталкивается обычный программист, никакая алгебра, как правило, не подразумневается, и этот термин используется лишь потому, что в словосочетании «многомерный массив» слишком много букв.
Пусть линейной функции \(f\) соответствует матрица \(A\), а функции \(g\) соответствует матрица \(B\). Тогда композиции этих функций \(h = f \circ g\) будет соответствовать произведение \(C\) матриц \(A\) и \(B\), определяемое следующим образом:
\[ C = AB: \; C_{ij} = \sum_{i=1}^{k} A_{ik} B_{kj} \]
Читатель может убедиться в этом, расписав, какие коэффициенты получаются, если формулы из \(g\) подставить в \(f\).
При перемножении матриц руками удобно думать так: элемент на пересечении \(i\)-го столбца и \(j\)-той строки — это скалярное произведение \(i\)-той строки \(A\) и \(j\)-того столбца \(B\). Заметим, что это накладывает ограничение на размерности перемножаемых матриц: если первая матрица имеет размер \(n \times k\), то вторая должна иметь размер \(k \times m\), то есть «средние» размерности обязательно должны совпадать.
Исходное выражение для \(f(x)\) теперь можно компактно записать как \(f(x) = Ax\) вместо \(m\) уравнений с \(n\) слагаемыми в каждом.
Напишем функцию, реализующую матричное умножение:
const int n, k, m;
matrix matmul(matrix a, matrix b) {
matrix c(n, vector<int>(m, 0));
for (int i = 0; i < n; i++)
for (int j = 0; j < m; j++)
for (int t = 0; t < k; t++)
c[i][j] += a[i][t] * b[t][j];
return c;
}Такая реализация хоть и наиболее простая, но не оптимальная ввиду особенностей работы кэша (см. раздел «Оптимизации матричного умножения»).
К матрицам не нужно относиться как к табличкам, в которых стоят какие-то числа. Каждой матрице соответствует какая-то линейная функция, как-то преобразующая вектора. Центральными объектами линейной алгебры являются именно линейные функции, а не матрицы.
Благодаря этому взаимно однозначному соотношению все ранее упомянутые свойства линейных функций переносятся и на матрицы:
Есть специальная матрица \(I\) (иногда обозначается \(E\)), которая называется единичной и относительно умножения ничего не делает, то есть ведёт себя как единица. У неё единицы на главной диагонали и нули вне неё:
\[ I_3 = \begin{pmatrix} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \\ \end{pmatrix} \]
Некоторые линейные функции обратимы (например, поворот на угол), некоторые — необратимы (например, проекция). Понятие обратимости можно продолжить и на матрицы.
Определение. Матрица \(A\) является обратимой, если существует матрица \(A^{-1}\) такая, что \(A \cdot A^{-1} = A^{-1} \cdot A = I\).
Из формулы следует, что матрица \(A\) должна быть квадратной, но этого не всегда достаточно. У неквадратных матриц обратных матриц не существует. Обратную матрицу можно находить за \(O(n^3)\) методом Гаусса, который будет рассмотрен чуть позже.
Матрица «увеличь всё в два раза»:
\[ \begin{pmatrix} 2 & 0 & 0 \\ 0 & 2 & 0 \\ 0 & 0 & 2 \\ \end{pmatrix} \]
Матрица «поменяй \(x\) и \(y\) местами»:
\[ \begin{pmatrix} 0 & 1 \\ 1 & 0 \\ \end{pmatrix} \]
Матрица поворота на угол \(\alpha\) на плоскости:
\[ \begin{pmatrix} \cos \alpha & -\sin \alpha \\ \sin \alpha & \cos \alpha \\ \end{pmatrix} \]
Матрица проецирования на плоскость \(xy\) в трёхмерном пространстве:
\[ \begin{pmatrix} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 0 \\ \end{pmatrix} \]
Пока что все примеры были про геометрию. Так просто проще думать: представлять в уме повороты и растяжения векторов на плоскости легче, чем рассуждать о свойствах абстрактных n-мерных пространств.
Однако мы программисты, и нас в основном интересуют задачи вне геометрии.
Переходы в некоторых динамиках иногда можно выразить в терминах матричного умножения.
Рассмотирм конкретный пример. Пусть у нас есть ориентированный граф \(G\), заданный своей матрицей смежности, и нам нужно найти количество путей из \(s\) в \(t\) через ровно \(k\) переходов. Размер графа маленький по сравнению с \(k\) (скажем, несколько сотен вершин, в то время как \(k\) это число порядка \(10^{18}\)).
Обычно, мы бы ввели динамику \(f_{i,v}\), равную количеству способов дойти до \(v\)-той вершины через ровно \(i\) переходов. Пересчёт — перебор предпоследней вершины в пути:
\[ f_{i,v} = \sum_u f_{i-1,u} \cdot G_{uv} \]
Выясняется, что вектор \(f_{i}\) зависит от \(f_{i-1}\) линейно: его \(v\)-тый элемент получается скалярным умножением \(f_{i-1}\) и \(v\)-того столбца матрицы смежности \(G\).
Значит, имеет место следующее равенство:
\[ f_i = f_{i-1} G \]
(Поэтому \(G\) и называют матрицей смежности.)
Получается, \(f_k\) можно раскрыть как \(f_k = f_0 \cdot G \cdot G \cdot \ldots \cdot G\). Вспоминая, что умножение матриц коммутативно, по аналогии со скалярами для вычисления \(G^k\) мы можем применить бинарное возведение в степень:
\[ A^8 = A^{2^{2^{2}}} = ((AA)(AA))((AA)(AA)) \]
По этой формуле нам нужно \(\log k\) раз перемножить две матрицы размера \(n\), что суммарно будет работать за \(O(n^3 \log k)\).
const int n;
matrix binpow(matrix a, int p) {
// создадим единичную матрицу
matrix b(n, vector<int>(n, 0));
for (int i = 0; i < n; i++)
b[i][i] = 1;
while (p > 0) {
if (p & 1)
b = matmul(b, a);
a = matmul(a, a);
p >>= 1;
}
return b;
}В получившейся матрице в ячейке \(g_{ij}\) будет находиться количество способов дойти из \(i\)-той вершины в \(j\)-тую, используя ровно \(k\) переходов. Ответом нужно просто вывести \(g_{st}\).
Модификации задачи:
Практически не меняя сам алгоритм, можно решить задачу «с какой вероятностью мы попадём из вершины \(s\) в вершину \(t\)», если вместо булевой матрицы смежности даны вероятности, с которыми мы переходим из вершины в вершину в марковской цепи.
Если нам не нужно количество способов, а только сам факт, можно ли дойти за ровно \(k\) переходов, то можно обернуть матрицу в битсеты и сильно ускорить решение.
Если нас спрашивают «за не более, чем \(k\) переходов», то вместо \(k\)-той степени матрицы мы можем подобным методом посчитать сумму геометрической прогрессии.
Эту технику можно применить и к другим динамикам, где нужно посчитать количество способов что-то сделать — иногда очень неочевидными способами. Например, можно решить такую задачу: найти количество строк длины \(k \approx 10^{18}\), не содержащих данные маленькие запрещённые подстроки. Для этого нужно построить граф «легальных» переходов в Ахо-Корасике, возвести его матрицу смежности в \(k\)-тую степень и просуммировать в нём первую строчку.
В некоторых изощрённых случаях в матричном умножении вместо умножения и сложения нужно использовать другие операции, которые ведут себя как умножение и сложение. Пример задачи: «найти путь от \(s\) до \(t\) с минимальным весом ребра, использующий ровно \(k\) переходов»; здесь нужно возводить в \((k-1)\)-ую степень матрицу весов графа, и вместо обеих операций использовать минимум матрице весов графа.
Расмотрим другой пример — последовательность Фибоначчи. Ну а чем не динамика?
\[ f_{n} = f_{n-1} + f_{n-2} \]
Как мы видим, \(n\)-ный элемент линейно выражается через два предыдущих.
Вообще говоря, последовательностей Фибоначчи много — им не обязательно начинаться с \(0\) и \(1\). Для однозначной идентификации всей последовательности достаточно знать позиции и значения любых двух различных элементов. Поэтому в качестве состояния динамики введём такой вектор-столбец:
\[ \begin{pmatrix} f_{n+1} \\ f_{n+2} \\ \end{pmatrix} = \begin{pmatrix} 0 + f_{n+1} \\ f_{n} + f_{n+1} \\ \end{pmatrix} = \begin{pmatrix} 0 & 1 \\ 1 & 1 \\ \end{pmatrix} \begin{pmatrix} f_{n} \\ f_{n+1} \\ \end{pmatrix} \]
(Также можно «шагать» в обратном направлении, если обратить эту матрицу.)
Обозначим за \(A\) эту матрицу перехода. Чтобы посчитать \(n\)-ное число Фибоначчи, нужно применить \(n\) раз эту матрицу к вектору \((f_0, f_1) = (0, 1)\). Как и в предыдущем случае, мы можем воспользоваться бинарным возведением в степень: операция матричного умножения ассоциативна, поэтому применить \(n\) раз матрицу перехода к вектору равносильно одному применению к нему матрицы перехода, возведённой \(n\)-ную степень. Её можно посчитать за \(O(\log n)\), потому что размер матрицы на этот раз константный.
В общем случае, линейная рекуррента \(f_n = a_1 f_{n-1} + a_2 f_{n-2} + \ldots + a_k f_{n-k}\) имеет такую матрицу перехода:
\[ \begin{pmatrix} 0 & 1 & 0 & \ldots & 0 \\ 0 & 0 & 1 & \ldots & 0 \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & 0 & \ldots & 1 \\ a_k & a_{k-1} & a_{k-2} & \ldots & a_1 \\ \end{pmatrix} \]
Очень часто у матриц есть собственные векторы — те, которые не меняют направление при применении этой матрицы к ним.
\(Av = kv\), где \(k \neq 0\). Число \(k\) называется собственным числом матрицы.
\(Av - kv = (A-kI)v = 0\).
Вообще, собственные вектора в линейной алгебре имеют почти такое же значение, как простые числа в арифметике.
Базисом множества называется набор векторов, через линейную комбнацию которых единственным способом можно выразить все вектора этого множества и только их.
Базисы есть не только в линейной алгебре. Например, \(\{1, x, x^2\}\) является базисом всех квадратных трёхчленов. Или \(\{\neg, \land, \lor\}\) является базисом всех логических выражений (то есть всё можно выразить через И, ИЛИ и НЕ). В произвольном языке программирования можно выделить какой-то набор команд, через который можно будет написать всё что угодно, и он тоже в этом смысле будет базисом.
Система векторов \(\{a_1, a_2, \dots, a_n\}\) называется линейно зависимой, если существует такой набор действительных коэффициентов \((\lambda_1, \lambda_2, \dots, \lambda_n)\), что \(\lambda_j \neq 0\) хотя бы для одного \(j\) и \(\lambda_1 \cdot a_1 + \lambda_2 \cdot a_2 + \dots + \lambda_n \cdot a_n = 0\). В противном случае система называется линейно независимой. Например, базис \(N\)-мерного пространства - это линейно независимый набор из \(N\) векторов. (Доказательство: пусть базис линейно зависим. Тогда вектор нулевой длины можно выразить хотя бы двумя способами)
Два столбца (или две строки) матрицы называются линейно зависимыми, если два образованных ими вектора являются линейно зависимыми (коллинеарными). Рангом матрицы \(rang\) \(A\) называется максимальное число \(r\) такое, что можно выбрать \(r\) попарно линейно независимых столбцов или строк в матрице.
Иногда встречаются задачи, требующие решения системы линейных уравнений. Очень большая часть из них на самом деле над полем \(\mathbb{Z}_2\) — то есть все числа по модулю 2. К примеру: есть \(n\) переключателей лампочек, каждый активированный переключатель меняет состояние (включает или выключает) какого-то подмножества из \(n\) лампочек. Известно состояние всех лампочек, нужно восстановить состояние переключателей.
Нас по сути просят решить следующую систему:
\[ \begin{cases} a_{11} x_1 + a_{12} x_2 + \ldots + a_{1n} x_n \equiv b_1 \pmod 2\\ a_{21} x_1 + a_{22} x_2 + \ldots + a_{2n} x_n \equiv b_2 \pmod 2\\ \ldots \\ a_{n1} x_1 + a_{n2} x_2 + \ldots + a_{nn} x_n \equiv b_n \pmod 2 \end{cases} \]
Здесь \(x\) — состояния переключателей, \(b\) — состояния лампочек, \(A\) — информация о том, влияет ли переключатель на лампочку.
Метод Крамера неоптимален — там \(O(n^4)\) операций.
В таком случае можно значительно ускорить и упростить обычный метод Гаусса:
t gauss (matrix a) {
for (int i = 0; i < n; i++) {
int nonzero = i;
for (int j = i+1; j < n; j++)
if (a[j][i])
nonzero = j;
swap(a[nonzero], a[i]);
for (int j = 0; j < n; j++)
if (j != i && a[j][i])
a[j] ^= a[i];
}
t x;
for (int i = 0; i < n; i++)
x[i] = a[i][n] ^ a[i][i];
return x;
}Код находит вектор \(x\) из уравнения \(Ax = b\) при условии, что решение существует и единственно. Для простоты кода, предполагается, что вектор \(b\) приписан справа к матрице \(A\).
Часто эту систему нужно решить по модулю 2. Тогда код значительно упрощается и ускоряется (опять же, см. Битсет).
Наивная реализация матричного умножения из начала статьи неоптимальна из-за паттерна обращения к элементам b: мы каждый раз двигаем указатель в памяти на \(m\) шагов вперёд, что приводит к лишним загрузкам кэш-линий и не позволяет компилятору применить автовекторизацию.
Однако, чтобы это исправить, достаточно перед всеми циклами транспонировать b, то есть поменять каждый её \((i, j)\)-тый элемент на \((j, i)\)-тый (пусть, для определённости, \(i < j\)). Такая реализация будет работать в ~5 раз быстрее, и её уже довольно трудно соптимизировать дальше.
Дальше трудности возникают лишь при работе большими матрицами, которые не помещаются целиком в кэш — мы ведь для каждой строчки \(C\) каждый раз заново проходимся по всем элементам \(A\) и \(B\). Тогда можно поступить следующим образом: разделить матрицы \(A\) и \(B\) на, например, 4 равные части, и перемножить блочно:
\[ AB = \begin{pmatrix} A_{11} & A_{12} \\ A_{21} & A_{22} \\ \end{pmatrix} \times \begin{pmatrix} B_{11} & B_{12} \\ B_{21} & B_{22} \\ \end{pmatrix} = \begin{pmatrix} A_{11} B_{11} + A_{12} B_{21} & A_{11} B_{11} + A_{12} B_{21} \\ A_{11} B_{11} + A_{12} B_{21} & A_{11} B_{11} + A_{12} B_{21} \\ \end{pmatrix} \]
При рекурсивном вычислении этой формулы кэш будет использован оптимально вне зависимости от его размера, а также размера кэш-линии (такие алгоритмы называют cache-oblivious).
Наука знает и более быстрые способы перемножить матрицы, но они имеют весьма большую константу, и более эффективны только на матрицах от тысяч элементов. На практике достаточно транспонирования одной из матриц и итерации по второй размерности во всех трёх массивах.